Deep and Wide Research with Transparent AI: A Structural Alternative to LLM-Based Agents.

In the evolving landscape of artificial intelligence (AI), there is an increasing tension between the promise of agentic LLM-based systems and their real-world research limitations. While large language models (LLMs) excel at generating fluent text, their capacity to support rigorous, enterprise-grade research remains fundamentally constrained.
Recent failures in commercial settings underscore this gap: tools marketed as “Deep Research” have been shown to produce confidently presented but systematically flawed results, culminating in high-profile cases such as Deloitte’s refund to the Australian Government following the discovery of AI-generated inaccuracies in a major report¹.
Notably, even the LLM developers themselves acknowledge these constraints. All outputs come with a health warning, and benchmark results they have published have long highlighted the challenge of accurate automated research. OpenAI Deep Research had 51.5% accuracy on their BrowseComp benchmark when tuned for the benchmark². In the real world, without the tuning, expect the results to be worse.
In contrast, evidence-led, transparent AI builds structured knowledge graphs from verifiable sources, enforces cross-validation, and preserves provenance. Glass.AI demonstrates that such an approach can scale to large, multi-domain research tasks while mitigating cumulative error, producing auditable and reproducible outputs.
Why Agentic LLMs Struggle at Real Research
Real research tasks typically demand both breadth and depth: an agent must identify relevant sources across domains, verify claims, and reason over linked facts. But current LLM agents struggle to sustain this process reliably. They tend to either skim too shallowly or collapse under the burden of long, multi-step evidence chains where each inference step introduces probabilistic error. In long pipelines, these errors compound, resulting in near-zero overall reliability for complex tasks³.
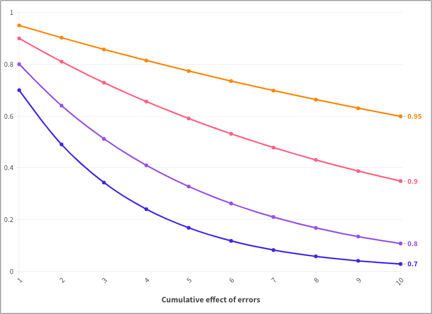
When operating at web scale, even moderate model inaccuracy becomes amplified. As the chart shows, an AI model with 70–80% accuracy on individual subproblems may, when combined across ten steps, yield an overall accuracy of less than 20%. Even at a target of > 95% per step, well above current norms, the chance of full-path correctness can fall significantly.
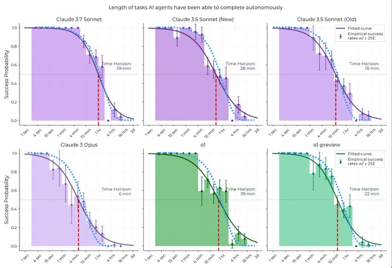
Earlier in the year, a paper measured the ability of AI to complete running long tasks⁴. One conclusion drawn from this research was that the AI time horizon of these long tasks was doubling every seven months, and it was getting exponentially better. Tony Ord took a different view⁵. Drawing on the same data, Ord shows that agents’ success probability decays in proportion to task length — the longer a task, the more likely one failure among its many micro-steps will derail the entire process. He models this with a simple exponential “half-life”: if an agent fails at some constant rate per minute (or per subtask), then the probability of overall success declines quickly.
Reinforcing the cumulative effect of errors on long-running tasks, this “half-life” effect is deeply concerning for research-oriented use cases. High-stakes tasks such as due diligence, policy analysis, or business strategy research involve many conditional steps. If the architecture itself compounds risk with every extra layer or minute, then even advanced agents will systematically underperform in realistic environments.
DeepWideSearch Benchmark: Empirical Evidence of Structural Limits
The recent DeepWideSearch benchmark published by Alibaba⁶ offers one of the clearest tests of whether LLM agents can integrate depth and breadth in information-seeking. The benchmark requires agents to perform both wide evidence collection and deep multi-hop reasoning across a curated corpus of domain-diverse questions.
The results were unequivocal. State-of-the-art agents achieved only 2.39% average success.

Failure modes were consistent and revealing:
Insufficient retrieval as agents fail to gather necessary evidence.
Overreliance on internal knowledge as hallucinations fill gaps where evidence is missing.
Lack of reflection as agents do not revise or verify their intermediate steps.
Context overflow occurs when evidence chains exceed model and context limits.
These limitations are not addressed by simple scaling. They stem from the architecture itself: LLM agents infer rather than verify, compress rather than retain provenance, and often substitute fluent reasoning for evidential grounding.
The Cumulative Error Challenge in Multi-Step Pipelines
The cumulative error effect, observed both in empirical benchmarks and Glass.AI’s operational experience, poses a fundamental challenge for LLM-based research systems. Long, conditional research processes required for any enterprise-grade research are particularly vulnerable.
Every stage (retrieval, extraction, summarisation, inference, ranking, synthesis) introduces a risk of failure. Since most stages depend on the correctness of earlier ones, even small error probabilities compound to catastrophic failure rates. This aligns directly with the half-life model: longer tasks are disproportionately harder, not because of their conceptual difficulty but because of the accumulation of micro-failures.
Evidence-Led, Transparent AI: A Structural Alternative
Glass.AI employs an architecture designed explicitly to break the cumulative-error cycle. Its approach is grounded in structured evidence ingestion, not internal inference:
Web-scale ingestion of documents across news, corporate sites, reports, datasets, and sector-specific sources.
Extraction and structuring of entities, claims, and relationships into an evolving knowledge graph.
Cross-validation using ensembles of specialist models, ensuring that no single model’s error propagates unchecked.
Full provenance tracking, enabling every datapoint to be traced back to its source document and extraction method.
Human-in-the-loop quality gates, applied where model ambiguity or risk is highest.
Flexible, modular pipeline that adapts to context-specific combinations where small differences matter.
Depth is achieved through multi-hop linking of verified claims. Width is maintained through continuous large-scale crawling. Crucially, the architecture prevents error accumulation: incorrect or uncertain claims are challenged, cross-validated, or removed before they can poison downstream results.
This results in research outputs that are reproducible, traceable, and auditable³.
Conclusion
Recent benchmarks such as DeepWideSearch, alongside theoretical analyses like the task-completion half-life model, reveal structural limitations in LLM-based agentic systems. These models cannot reliably maintain accuracy over the long, conditional, multi-step processes foundational to serious research.
Evidence-led, transparent AI, as offered by Glass.AI, provides a fundamentally different paradigm. By grounding every inference in verifiable evidence, enforcing cross-validation, and maintaining end-to-end provenance, it avoids the cumulative-error dynamics that undermine LLM-based pipelines.
Further, this architecture enables deep and wide research not as a generative task but as a knowledge construction process. Built from primary evidence, the outputs constitute first-party research that can support genuinely novel analysis, rather than derivative summaries of existing material.
For domains where accuracy, traceability, and interpretability are essential (e.g. government research, consultancy, due diligence, risk analysis), this architectural shift is not optional. It is necessary. Only evidence-led systems provide the stability and fidelity required for meaningful decision-making in complex environments.
[1]: Financial Times. Deloitte issues refund for error-ridden Australian government report that used AI. https://www.ft.com/content/934cc94b-32c4-497e-9718-d87d6a7835ca. Oct 6, 2025.
[2]: OpenAI. BrowseComp: a benchmark for browsing agents. https://openai.com/index/browsecomp/. April 10 2025.
[3]: Glass.AI. A Case Study in “Agentic” AI — Automating Sector and Places Research For Governments. https://www.glass.ai/glass-news/a-case-study-in-agentic-ai-automating-sector-research-for-governments-and-consultancies-shlxg. Jul 12 2024.
[4]: T. Kwa et. al. Measuring AI Ability to Complete Long Tasks. https://arxiv.org/abs/2503.14499. Mar 30, 2025.
[5]: T. Ord. Is there a Half-Life for the Success Rates of AI Agents? https://www.tobyord.com/writing/half-life. May 7, 2025.
[6]: T. Lan. DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking. https://arxiv.org/abs/2510.20168.Oct 23 2025.