The Evidence Discovery Problem in Agentic Research Systems.
Agentic deep research systems are becoming increasingly capable of reasoning. Given the right evidence, frontier models can synthesise nuanced answers, identify implicit relationships, and verify subtle patterns with remarkable accuracy.
However, the recent OBLIQ-Bench paper¹ highlights a more fundamental limitation in modern AI research systems: the gap between reasoning capability and evidence retrieval.
OBLIQ-Bench makes an uncomfortable but important point. Many failures in real-world research systems do not come from reasoning at all. They come from what is never retrieved in the first place. The model can often recognise relevance once it sees the evidence. The problem is that, in many cases, it never sees it. This is also where hallucinations tend to emerge, as systems attempt to fill missing context with internal priors.
When retrieval fails on “oblique” queries
OBLIQ-Bench introduces a class of problems it calls oblique queries: cases where relevance is not explicitly signalled. Instead, it is latent, indirect, or distributed across weak signals.
These are not traditional keyword-based retrieval tasks. The relevant information may be:
implied rather than explicitly stated
distributed across multiple fragments of evidence
expressed in non-obvious or domain-specific language
only recognisable through analogy or structural similarity
This is where modern retrieval systems begin to break down. Dense retrieval and re-ranking can handle straightforward semantic similarity, but they struggle when relevance depends on structure rather than surface meaning.
This is clearly illustrated in the OBLIQ-Bench analysis: embedding-based retrieval and stronger re-rankers can show surprisingly low overlap in what they consider relevant, as demonstrated in the following diagram from the OBLIQ-Bench paper, where a Gemini embedding-based retriever is covering a different space than the GPT5.2-based reranker for a range of research tasks.
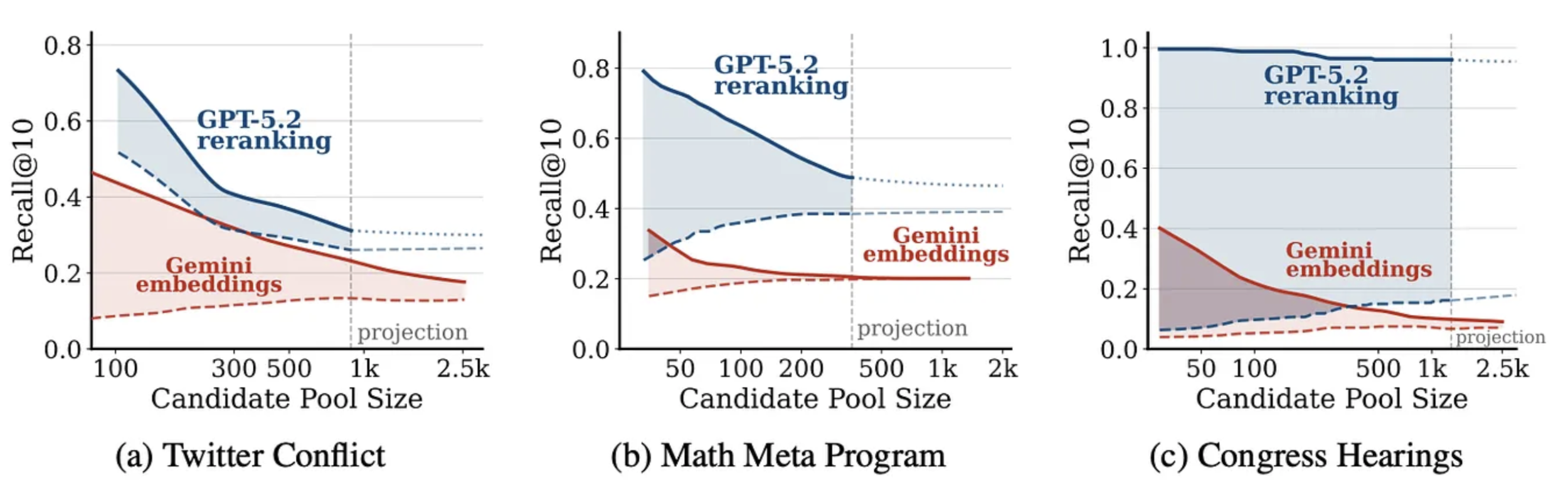
In practice, this leads to a consistent failure mode; highly relevant documents exist in the corpus, but are never surfaced into the candidate set. Once that happens, no amount of re-ranking or reasoning can recover them.
The retrieval verification mismatch
This distinction matters because many modern RAG and agentic research systems implicitly assume that retrieval is largely solved. Still, OBLIQ-Bench shows that the boundary between retrieval and re-ranking is precisely where relevant evidence is lost or distorted.
It works reasonably well for explicit factual lookup and short-horizon question answering. But it becomes far less reliable for complex research tasks where evidence is diffuse, weakly signalled, or buried deep within noisy corpora.
This issue becomes especially visible in long-horizon research tasks, particularly in business and strategic analysis. The most valuable signals are rarely explicit. Instead, they tend to appear as weak, fragmented indicators distributed across time and sources.
For example, identifying early signals of strategic change in a company might require combining:
hiring patterns that suggest a shift in capability
subtle changes in product or marketing language
procurement or partnership activity
other scattered external commentary
Individually, none of these signals is decisive. Together they form a pattern, but only if they are retrieved in the first place.
This is where OBLIQ-Bench is particularly relevant. It shows that these signals are precisely where modern retrieval systems are weakest. The consequence is not primarily misinterpretation. It is an absence. Systems fail because they never retrieve the most important evidence at all.
How this shows up in practice
In real-world research workflows, this mismatch produces a familiar pattern of failure. Surface-level or high-salience documents dominate the context, while subtler but more relevant signals are missing. The model is then forced to reason over an incomplete evidence set.
This leads to two secondary effects that are easy to overlook:
First, models begin to over-rely on internal priors when external evidence is missing, increasing the likelihood of hallucination or overconfident inference.
Second, early retrieval errors compound over longer reasoning chains, progressively degrading output quality as the research task unfolds.
In other words, small retrieval misses do not remain small. They shape the entire downstream reasoning process.
The structural causes of evidence discovery failure
Modern agentic systems often perform well on bounded tasks with clear retrieval targets, but degrade rapidly when evidence chains become broader, noisier, or more ambiguous.
Recent benchmarks such as OBLIQ-Bench and Deep Research evaluations² consistently expose similar structural weaknesses: insufficient retrieval coverage, overreliance on model priors when evidence is missing, brittle query decomposition, context overflow, and failure to recover overlooked information hidden in the long tail.
These are not merely prompting issues. They are architectural limitations. They emerge when systems are optimised primarily for reasoning over a small retrieved context window, rather than for robust evidence discovery and management across a wider information space.
In many cases, modern research agents behave less like researchers and more like sophisticated summarisation systems operating over incomplete evidence sets.
Why Glass.AI approaches this differently
This is exactly why Glass.AI has always approached research differently from many recent agentic systems.
Rather than treating research primarily as a retrieval and reasoning workflow, Glass.AI treats it as an iterative evidence system. The focus is not only on finding “relevant documents,” but on systematically surfacing, connecting, and validating weak and indirect signals that become meaningful when viewed together.
In practice, this shifts the system from a simple retrieval pipeline into a structured research process involving:
broad and iterative evidence collection
entity-centric enrichment across sources
cross-document linking of related signals
transparent evidence provenance
continuous refinement of hypotheses as new evidence emerges
The key distinction is not simply that the system retrieves more evidence or retrieves iteratively. Its research is built around accumulating and connecting evidence over time, while maintaining visibility into how conclusions are formed and what evidence supports them.
This becomes increasingly important for long-horizon research tasks, where relevance is often distributed across many small fragments rather than contained within a single highly-ranked result. As evidence chains become more complex, understanding why a conclusion was reached becomes almost as important as the conclusion itself.
Beyond agents
The OBLIQ-Bench results reinforce something that becomes increasingly clear at scale: retrieval quality defines the ceiling of reasoning quality.
A highly capable model operating on incomplete evidence will still produce incomplete conclusions. As research workflows become more ambitious, the bottleneck shifts away from reasoning alone and toward the infrastructure used to discover, validate, enrich, and connect information.
This is why the next generation of deep research systems will likely depend less on autonomous agents alone and more on robust research infrastructure, systems designed for:
iterative evidence expansion
entity-level understanding and enrichment
provenance tracking
long-horizon memory
latent signal discovery
In many ways, this reflects a broader, older truth in information retrieval and intelligence analysis: finding the right evidence is often harder than interpreting it. As reasoning systems improve, the bottleneck in deep research is shifting from understanding evidence to reliably discovering it in the first place.
- - - - - - - - -
[1]: D. Tchuindjo, D. Shah, and O. Khattab. OBLIQ-Bench: Exposing Overlooked Bottlenecks in Modern Retrievers with Latent and Implicit Queries.https://arxiv.org/abs/2605.06235. May 7 2026.
[2]: T. Lan. DeepWideSearch: Benchmarking Depth and Width in Agentic Information Seeking. https://arxiv.org/abs/2510.20168. Oct 23 2025.